03:关于MiX Copilot的一些思考
什么是知识?或者说信息、知识、智慧之间的关系是什么?我觉得有张图概括得挺好的: 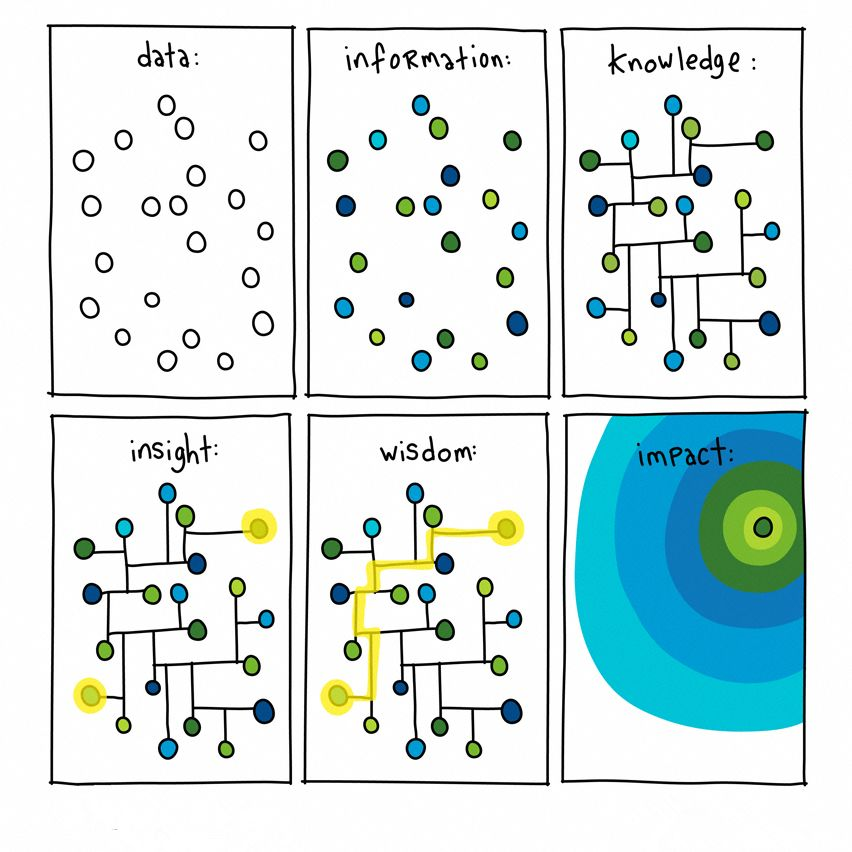 以下我引用了一位博主写的内容:
以下我引用了一位博主写的内容:
如果是代表了巴菲特的思考,那么:
1.杂乱无章的股票交易数据(Data),经过简单整理,变成了股票市场上的信息(Information)。 在这时,巴菲特和其他投资者一样,看到的是每只股票的交易、价格、财务报表等信息。
2.加工信息,使之形成体系,即为知识(Knowledge)。 巴菲特之前的操盘手和投资家们,将股票市场上大量信息反映出的规律,总结归纳成一套方法论,并可在未来持续使用。注意,99%的交易者都会看到同样的信息,可是只有1%的人,会去学习背后的知识,例如江恩、道氏、波浪等理论,财务、基金、证券等相关的知识。
3.知识是一个宫殿,洞见(Insight)就是找到宫殿里的出口。 要知道,在美国上市的公司有超过7000家,如何从大量的公司、不断变化的信息中挑选出最有价值的公司?这就是巴特菲长期形成的洞见,或者可以称之为:投资大师的眼光。
4.找到知识宫殿的最短(有效)路径,称作智慧**(Wisdom)****。** 什么是股票投资的最短路径?对巴菲特来说,毫无疑问就是他的价值投资理论。 利用这套理论,他总是能够找到收益可观的股票,并且在时间的长河中反复被验证。
5.传播自己的智慧,营造出自己的影响力圈子(Impact)。
MiX Copilot的定位是一款“知识引擎”,它的目的是将零散的数据(Data)转换成各种对你有帮助的洞见(Insight),并且方便你分享出去,所以MiX Copilot的中文Slogan是“非凡想法,源于洞见”,英文是“Effortlessly Transforming Intelligence into Extraordinary Ideas”。你可能会说这是一个很务虚的说法,具体怎么实现呢?大家可以期待一下我们未来的工作,大概率在9-10月份的时候你们会看到很新的东西。
通过16个月的时间,我们基本将MiX Copilot的基建搭建好,例如定时自动运行的多线程爬虫、一键生成卡片和导出Markdown、Agent模块、支付系统等等。尽管我们花了大量时间构建基础,但我们的成就依然是可圈可点的。例如MiX Copilot的LLM工作流编辑器是在23年5月底上线的,无论是浏览器扩展还是PC软件,都是全球第一个推出的商业化产品,而且MiX Copilot是第一款拥有完整场景和闭环的LLM客户端。 
尽管我很不喜欢国内厂商天天吹捧自己”第一“的坏习惯,但从时间上我们确实做到了第一。当中国厂商都在卷大模型基建、微调、RAG的时候,我们的时间都花在用户体验和场景验证上。因为在我和Shadow眼里,在LLM时代下你跑得再快也跟不上技术迭代的速度,所以最佳的方法是尽快拉近和用户的距离。
MiX Copilot 1.0是一款浏览器插件,它具有独立且完整的Chatbot系统、LLM工作流编辑器以及控制浏览器。没错,我们在23年5月份的时候已经可以让LLM完成工作后自动操控浏览器了,例如在浏览网页的时候,我点击一个按钮就可以将网页内容进行总结并通过模拟事件发送到知识星球。还有我们的工作流和角色可以直接在新建标签页使用。
不知道哪个贱人在7月份恶意举报我们导致我们的应用被Chrome商店下架,被迫让我们开发了桌面端MiX Copilot 2.0。由于当时我们已经有一批付费用户,我们不能让我们的老用户等待太久,所以我们在1个月内完成了2.0版本的开发。这个版本有两个很重要的功能,它们分别是知识矿工和知识管家,顾名思义就是可以自动爬取和整理知识,这也让MiX Copilot 2.0成为是全球第一个爬虫+LLM自动整理的产品,无论是商业还是开源项目。对了,它也是当时全球范围内为数不多可以支持本地LLM的桌面端应用。
MiX Copilot 2.0初步承载了我和Shadow的最早想法:信息应该是自动收集而不是每时每刻都要自己去每个网站浏览,同时不同的信息可以被不同的LLM工作流自动整理。为了验证用户是否有这么高级的需求,我们推出了预定服务,售价是199到399,在2周不到的情况下有接近200人购买了我们的知识矿工和知识管家。BTW,这个售价在中国互联网是比较罕见的。
由于MiX Copilot 2.0开发时间比较仓促(当时我和shadow还要给学生讲课),功能和体验并不是很完善,所以我们在9月份中旬推出了MiX Copilot 2.5,它可以被定义为AI浏览器,也就是说我们做了一个拥有多窗口+LLM交互的浏览器,它是全球第二个AI浏览器(因为Edg在此之前已经将Copilot搭载到它的浏览器上)。
本质上我们并不是要做一个AI浏览器,我们当时的做法是为了降低用户的理解门槛才选择了浏览器的形态:多窗口切换放在顶部。我个人认为,开发一个AI浏览器对于初创公司来说是一个极其愚蠢的决定,或者说只有想不开的产品经理才会做一个AI浏览器出来。为什么?
因为用户对于浏览器有着根深蒂固的理解:它是一款免费产品,而且长时间的使用导致用户不会轻易更换浏览器,更何况Google等厂商一定会掏出自己的AI浏览器出来。所以将自己定位成AI浏览器,要么是想通过获取用户数据达到其他目的,要么就是产品团队没清楚匆忙上线,要么就是觉得自己能干掉传统浏览器厂商,祝某些产品经理好运:-)
为了彻底扭转用户觉得我们是一个AI浏览器,同时解决信息架构上的一些问题,我们在4月份的时候迎来了交互框架上的大改版。当然,MiX Copilot 4.0会有更重大的变化,敬请期待。 

为什么说MiX Copilot是第一款拥有完整场景和闭环的LLM客户端?我并不是夸夸其谈或者讽刺友商。在我看来,LLM最终一定要跟系统交互,单凭网页交互是无法做深的,所以它最起码是个浏览器插件。但是浏览器插件的问题在于它拿不到系统权限,所以LLM必须是一个桌面客户端。如何理解LLM能在完整场景下实现闭环?以下是我的思考:
- 它具备上下文监听和理解能力。
- 用户可以自定义自己的需求。
- LLM的交互方式不只是一个Chatbot。
- 它能在离线环境下运行。
现在绝大部分的LLM客户端根本不具备上下文监听的能力,就像Chatgpt的客户端,准确讲它们不能做这个事情,因为要做到很自然的交互需要大量的系统权限和监听,这时候GDRP过不了。所以能做上下文监听的应用一定来自于操作系统厂商,例如微软的全家桶。对于我们来说,MiX Copilot完全不需要顾及应用外的上下文是什么,因为我们的输入是我们源源不断收集的信息。即使需要,我们都是用最简单的权限就可以做到。
第二点很好理解,目前这个只能通过蓝图编辑器去实现,也就是像MiX Copilot、Dify和Coze的编辑器,如果无法自定义需求,那可以理解为在任何场景下LLM都在做同一件事情。
第三点其实也很好理解,但我不是很能理解为什么大家就这么喜欢Chatbot的方式...说明设计者真的不理解如何结合场景进一步提高效率,如果感兴趣的设计师可以看看我过往写的GUI、VUI和Conversation UI的相关内容。
第四点就很不好理解了,目前全球能支持本地LLM的商业客户端可能10款都不到,明明都是调用兼容OpenAI格式的API,但就是不允许自行填写API URL。为什么?可能厂商喜欢收集数据?
尽管MiX Copilot的每个用户每天会消耗百万甚至到亿级别的Token,但MiX Copilot就不会收集用户的交互数据。你可能会觉得我写的数据很夸张,你想象一下每天几百篇文章和论文需要处理就知道我不是瞎说了。
我们不收集用户数据的原因很简单,第一,我们认为隐私很重要,它应该得到保护;第二,我们是以极其低的成本来运作MiX Copilot,你可以理解人力和财力有限。BTW,正因为我们知道MiX Copilot是一只吞金兽,所以最好的解决方案还是使用本地LLM来完成一系列LLM的交互。第三,我们是以用户为中心去设计产品,这部分的思考会在第五篇提及。
基建完善好了,那么下一步MiX Copilot将聚焦于如何在知识领域为创作者进行创新,各位敬请期待。